CNN 기초용어
- Convolution 합성곱
- Channel 채널
- Filter 필터
- Stride
- Padding 패딩
- Pooling 풀링
- 관련 내용에 대한 이해가 필요하다면, 아래 링크 참고해보기
CNN, Convolutional Neural Network 요약
CNN 모델 구성요소
- Convolution 레이어
- 필터를 이용하여 입력 이미지로 부터 특징을 추출하는 수학적 연산
- ex) Convolved Feature

- Pooling 레이어
- 필터를 이용하여 입력 이미지로 부터 특정 범위의 값을 압축(연산)하여 특징을 추출
- ex) MaxPooling

- Fully connected 레이어(FCN)
- 2차원의 배열 형태 이미지를 1차원의 평탄화 작업(flatten)을 진행한 벡터를 하나의 벡터로 연결
- 모델의 의사결정(ex. 분류 태스크)을 진행하는 레이어
CNN 모델 이후의 컴퓨터 비전 모델 변천사
ILSVRC
- 매년 열리는 ImageNet Large-Scale Visual Recognition Challenge
- Classification, Detection, Localization, Segmentation 등 다양한 부분으로 개최
- 1000개의 카테고리, 100만개의 이미지 활용
- 2015년 기준 사람의 평균적인 성능을 뛰어넘음
AlexNet

- 네트워크가 2개로 분리되는 구조
- GPU를 최대한 활용하기 위해 나눠서, 각각 GPU에 학습시킴
- 11*11필터를 사용
- 상대적으로 많은 파라미터가 필요, 컴퓨팅 연산이 많이 필요
- Relu 활성화 함수를 사용
- 선형모델의 특징을 보존 (0보다 커도 그레디언트값을 그대로 가짐)
- 그레디언트와의 최적화가 쉬움
- 좋은 일반화 성능을 보임
- 기울기 소실 문제를 해결
- 5개 Convolution Layer, 3개 Dense Layer로 구성됨
- Data Augmentation, Dropout 등을 활용
- [추가 궁금증] 왜 큰 필터를 사용하고자 하는가?
- receptive field 늘리는 차원에서 사용
- 필터를 작은 것을 사용할 경우, 이미지 픽셀의 지역적 정보는 충분하겠지만, 전역적, 문맥적 정보가 부족할 것으로 예상됨
- 하지만, 지나치게 큰 필터를 사용할 경우, 파라미터수가 기하급수적으로 증가하여 연산을 부담을 주기 때문에 최대 7*7 필터까지만 사용
- ( receptive field(수용영역, 수용장)과 dilated convolution(팽창된 컨볼루션) )
VGGNet

- 기존에는 5_5, 11_11 필터들을 활용하였으나, 3*3필터만을 활용하여 Depth를 늘림 (Stride1 사용)
- 왜 3*3필터만 사용해도 충분한 것인가?
- Depth를 늘려 3_3필터를 두번 사용할 경우, 실제로는 5_5 필터를 한번 사용하는 것과 동일. 대신에 필터를 두번사용할 경우 5*5필터를 사용함으로써 발생하는 파라미터 수 증가는 발생하지 않음

- 왜 3*3필터만 사용해도 충분한 것인가?
GoogLeNet

- Inception의 여러 버전 중 하나
(Inception 논문 https://arxiv.org/abs/1409.4842) - incpetion block을 활용해 network-in-network 구조를 취함

- 네트워크 안에 네트워크가 있는 구조로, 3*3필터를 통과하기 전에 1X1 필터를 먼저 통과 후 진행
- 왜 1X1필터를 사용하는 것인가?
- spatial dimension은 그대로 두고, 채널 수만 줄이는 구조이며, 파라미터 수는 확실하게 줄일 수 있음 (예시의 경우, 1/3로 줄임 147,456개 → 40,960개)
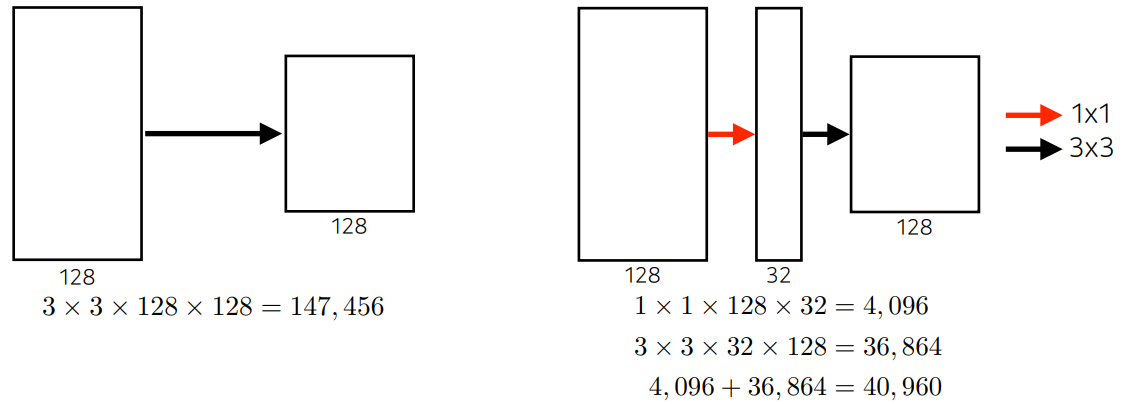
- [참고] 신경망은 Sparseity 해야지만 좋은 성능을 낼 수 있음 (ex. Dropout)
- [참고] 행렬 연산 자체는 Dense하게 처리해야 리소스 손실이 적음
- 추가적으로 1_1 컨볼루션 레이어를 통과시킨 것과 3_3 맥스풀링한 레이어 등등과 Concatenate를 진행
ResNet

- 기존의 SOTA 모델인 구글넷의 레이어수인 22개에서 레이어수가 152개로 급격한 증가
- 계속 네트워크는 깊어져도(Deeper) 상관없는 것인가?
- 과도한 숫자의 파라미터에 비해 오버피팅과 비슷한 현상이 발생
- 결과적으로 Train 성능 개선만큼, Test 성능 개선 미미
- 하지만, 기존과는 다른 구조를 취하여 이를 개선

- 계속 네트워크는 깊어져도(Deeper) 상관없는 것인가?
- 기존과 다른 Residual Block을 활용(Skip Connection)
- 기존의 네트워크는 단순히 Convolution 연산을 쌓는다면, ResNet은 블럭 단위로 파라미터로 전달하기 이전의 값을 더하는 방식

- 기존의 신경망은 입력값(x)를 타겟값(y)로 매핑하는 함수 H(x)를 얻는 것이 목적
- ResNet은 F(x) + x를 최소화하는 것을 목적
- 즉, x는 입력값으로 고정, F(x)를 0에 가깝게 만들어줌
- F(x) = H(x) -x 이므로 H(x) -x를 최소화하는 것과 동일(잔차를 최소화한다하여 ResNet)
- 새로운 구조를 통해 오버피팅 문제를 해결하여 더욱더 깊은 레이어를 통해 높은 성능을 달성
-

- 새로운 구조를 통해 오버피팅 문제를 해결하여 더욱더 깊은 레이어를 통해 높은 성능을 달성
DenseNet

- 레이어의 피처맵을 연결할 때, Resnet 구조와는 달리 덧셈이 아닌, Concatenate를 진행하여 정보를 보존(네트워크를 구분하여 정보를 보존)

- 이러한 구조를 통해 파라미터 수를 획기적으로 줄일 수 있음 (ResNet은 샘플링을 통해 파라미터 수를 줄일 수 있으나, 확실하게 줄일 수는 없음
- 피처맵을 재학습해야할 필요성 없어짐
- 기울기 소실 문제를 해결하여 더 Deep하게 쌓을 수 있음
- Dense 블록과 Trainsition 블록을 포함
- Dense 블록
- 풀링 연산을 위해 개념을 도임
- 여러 개의 레이어로 구성됨
- BatchNorm → relu → 3*3 Convolution 과정을 진행
- Trainsition 블록
- 피처맵의 크기와 채널 수(차원)를 감소시킴
- BatchNorm → 1_1 Convolution → 2_2 Average Pooling 과정을 진행
- Dense 블록
'Machine Learning' 카테고리의 다른 글
| [Knowledge Graph] 지식그래프 구축을 위한 사전지식 (0) | 2022.04.25 |
|---|---|
| Huggingface에서 AMP를 적용하는 방법 (0) | 2022.04.16 |
| 2022 국제인공지능대전(AI 엑스포) 방문기 (0) | 2022.04.16 |
| BERTAdam 옵티마이저의 진실 (3) | 2022.04.15 |
| [Multimodal] UniVL모델에서 사용된 MIL-NCE Loss (0) | 2022.04.10 |



